

CRM AnalyticsのEinstein Discoveryでは予測モデルを生成することができます。
しかし、予測モデルを試しに作成してみたところ、思ったより予測の精度が低く、
どうすればモデルの精度が改善するのか悩んでいる方もいるのではないでしょうか。
今回は数値予測モデルで参考にしたブログとそのなかで効果があった対応を紹介します。

数値予測モデルの品質改善で参考にしたブログ
Salesforceのデベロッパーブログ
予測モデルの品質改善: 全く意味のないモデルからそれなりに良いモデルに
バイナリ分類(商談成立/不成立といった2択の予測)に対して、
数値の予測モデルに関する記事はあまり見かけない印象です。
こちらの記事では数値予測モデルの改善例を挙げているため、とても参考になりました。
ブログの手法で効果があったものを3つ紹介
データの内容によると思いますが、過去に数値予測モデルで効果があったものを3つ紹介します。
外れ値除去
過去の対応で一番モデルのパフォーマンスに効果があったものは外れ値の除去でした。
これらの外れ値はモデルに大きな悪影響を与えます。
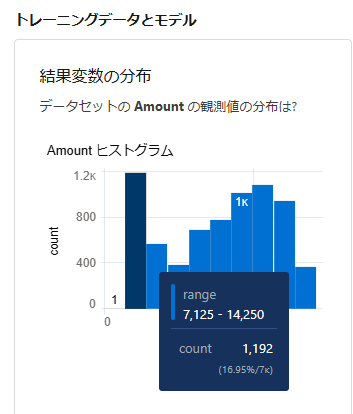
モデル画面でトレーニングデータとモデルの「結果変数の分布」を確認してください。
モデル画面>パフォーマンス>概要
金額など値の範囲が広くなると一つ一つのrangeも広くなります。
以下の例はTrailheadモジュール:Einstein Discovery の基本 のサンプルデータですが、
MAXが「71,250」です。
データに十万や百万の値があると値がばらけやすくなります。
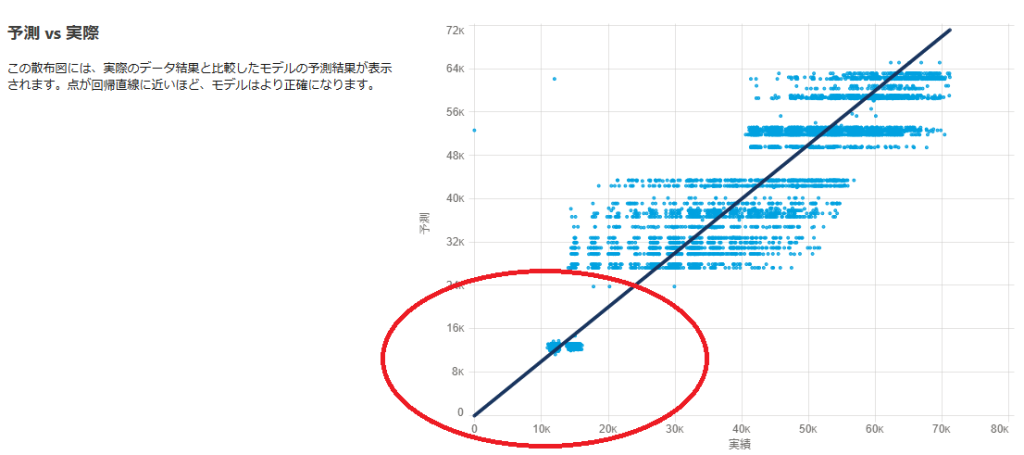
例えばモデルのパフォーマンス → モデル評価 → 全体的なパフォーマンスの「予測 vs 実際」で、
左下の方に点が集まっていて、右の方にポツポツと点が少し存在するような散布図となっている場合は、
最小値や最大値を絞って散布図の全体的に点がばらけるようになるといいと思います。
※縦は予測なので横の実績で見てみてください
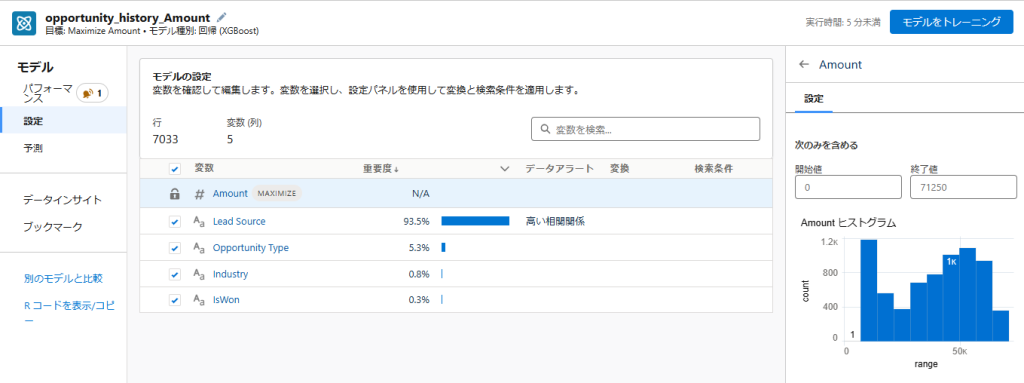
結果変数の値を絞るには、設定から結果変数を選択し、開始値と終了値を入力して
モデルをトレーニングします。
アルゴリズム変更
利用可能な学習アルゴリズムには「GLM」「GBM」「Random Forests」「XGBoost」の4種類があります。
特に指定がなければデフォルトで「GLM」が実行されます。
利用可能なアルゴリズムの種類について
- GLM(一般化線形モデル):
線形回帰モデルを拡張した統計モデル。
データの分布が直線状の正規分布に従わない場合でも柔軟に対応可能。 - GBM(勾配ブースティングマシン):
単純な予測モデルを組み合わせて、徐々に予測精度を高めていく手法。 - ランダムフォレスト:
多数の決定木をランダムに作成し、それらの予測を組み合わせることで、
より安定した高精度の予測を行う手法。 - XGBoost:
GBMを改良した高速で高性能なアルゴリズム。特に大量のデータを扱う際に効果的。
アルゴリズムの変更はデベロッパーブログの通り、モデルトーナメントを実行するのが簡単です。
数値予測モデルでは「XGBoost」アルゴリズムが一番効果があると書かれていますが、
実際に「XGBoost」で実行した場合がモデルのパフォーマンスがよかったです。
デフォルトで実行される「GLM」アルゴリズムでは多くのパターンで同じ予測結果が出ていましたが、
「XGBoost」アルゴリズムでは予測結果らしくなりました。
モデル画面の設定 → 一般設定 → アルゴリズム
選択リストからアルゴリズムを選択してモデルをトレーニングします
数値変数のバケッティングを調整する
モデルの作成で、「モデル列を設定」を 自動 にした場合、
数値変数に自動でバケッティングが設定されていると思います。
このバケットの設定を手動で調整するとモデルのパフォーマンスがわずかに改善することがありました。
大きな変化ではありませんが、試してみる価値はあると思います。
まとめ
数値予測モデルで参考にしたブログとそのなかで効果があった対応を紹介しました。
Salesforceでは専門知識がなくても精度の高いモデルが作成できるよう多くのサポート機能を
用意していますが、まだまだ敷居が高いように感じます。
今回紹介したポイントも「データアラート」で警告されるものですが、
最初はよく分からなかったことを覚えています。
この記事が少しでも参考になれば幸いです。









